DataOps
Description
DataOps (Data Operations) is a methodology whose goal is to improve the quality and reduce the development lifecycle of data analytics solutions – from ideation to creation of charts, graphs and models that generate value.
Purpose
The necessity for DataOps has emerged as enterprises realize that using all the data generated in the company can be a strategic asset, contributing to better decisions every day. DataOps is as much about the technology and the processes that govern it, as it is about changing people's relationship to data.
In general, DataOps aims to provide the following organizational benefits:
- accelerated rate of innovation
- reduced cost and time to insight
- keeping pace with changes in the company's domain of work
- increased collaboration and work reuse
Practices
Viewing DataOps from a practices’ perspective, it is a combination of Agile development, DevOps and Statistical Process Control. Applying these practices to digital data, results in DataOps.
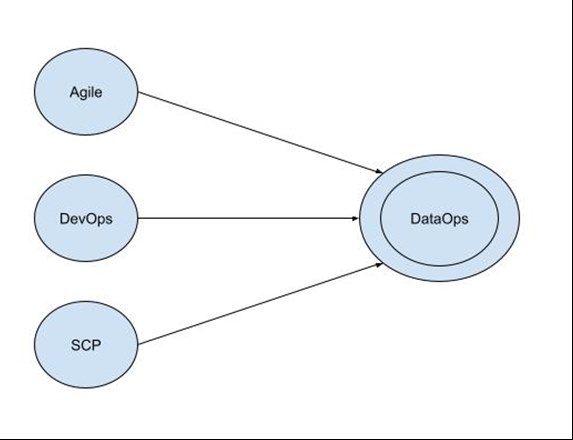
DevOps
The initial push for DataOps comes from DevOps. Development and Operations (DevOps) is a methodology that sits at the intersection between software development and IT operations. It focuses on the continuous integration, delivery and deployment of software products.
DataOps utilizes software engineering practices stemming from DevOps such as:
- everything-as-code – the ability to specify every part of the domain that is modelled as a piece of source code
- source code versioning – maintenance of an immutable audit log of how this source code changed over time. Source code versioning allows for reproducing every previous state with a pointer to the owner of each change.
- source code testing – a practice that serves to verify that software behaves according to specification. It helps developers gain confidence in their delivery and enables a faster development lifecycle by testing evolving source code against an ever-increasing battery of tests.
- deployment to multiple development environments – gives the ability to release software deliverables in isolation, preventing regressions in the product's functionality while allowing for multiple people to safely contribute product changes
- automation – automation is the use of technology to perform tasks with reduced human assistance. Simplifying change through automation gains companies the time and energy to focus on innovation. Freeing staff to focus on bigger issues, resolving them, and - in turn - making them routine and eligible for automation themselves.
Agile
For DataOps to be effective, it must support people by enabling better collaboration and faster innovation. Here is where the Agile development practices come into play. Agile as a process enables software development teams to produce new deliveries in short increments called "sprints." With innovation occurring in rapid intervals, the team can continuously reassess its priorities and more easily adapt to evolving requirements.
The following Agile practices apply to the DataOps methodology:
- work in small, empowered teams with clear roles – establishing teams that consist of individuals with all the skills required for delivery that span across disciplines
- deliver working software frequently, in short increments – leveraging the DevOps tools and practices, teams are enabled to deliver software at a high cadence
- get frequent feedback from Line of Business (LoB) – allows for business representatives to see the progress and guide the development from a domain expert perspective. The team gains confidence in the direction they have developed their software. The project as a whole becomes accepting of changing requirements and comes as closest to reality as technically feasible.
Statistical Process Control
Taking inspiration from LEAN manufacturing practice, DataOps adds the third piece to the methodology – Statistical Process Control (SPC). It measures, and monitors data and operational characteristics of the data pipeline, ensuring that statistics remain within acceptable ranges. When SPC is applied to data analytics, it leads to improvements in efficiency, quality and transparency. With it in place, the data flowing through the operational system is verified to be correct. If an anomaly occurs, the data team can be notified through automated alerting.
Data
The practices discussed so far put focus on how the software built to manipulate data can be implemented in a stable and maintainable way. It also focuses on the skills and practices needed in order to be successful.
These perspectives, however, don't address practices that reflect the inherent nature of data. Namely, it is domain knowledge captured in digital form. As such only domain experts can assess the true value it serves and its potential usages. Yet, these people typically lack the tools to make these findings. Furthermore, different contexts can view a single piece of data in a different manner. Hence, data has a binding effect on different contexts. Finally, data quality changes with time.
The following practices aim to address these properties:
- domain-driven design - data professionals need to work closely with the LoB in order to discover the ubiquitous language that the business uses, the bounded contexts that they use it in and the context mapping that describes how business representatives interact with one another. These findings need to power all processes interacting with data.
- contracts and dependency management - alongside its intended purpose as a quality business insight, a data asset also serves as a contract between its producer and consumer. In a growing landscape of data, these contracts play an important role in system integration and establishment of trust between system owners. Knowing the format of data, the cadence at which it is delivered in and its current deviation in comparison to that contract, are key parameters that allow data teams to place trust in these assets when making business decisions.
- feedback loops - in most enterprises, data flows unidirectional - from sources through data pipelines toward data warehouses, marts, and spreadsheets. The goal of a feedback loop is to give consumers the ability to communicate problems back to data stewards. This leads to systematic feedback mechanisms that enable data to flow from where it is consumed back up into the pipelines and all the way to the data sources.
Lifecycle
The Value Pipeline
Data analytics seeks to extract value from data - we call this the Value Pipeline. The Value Pipeline progressing horizontally from left to right where data enters the pipeline and moves into production processing. Production is generally a series of stages: access, transformation, and output e.g. models, visualizations and reports. When data exits the pipeline, in the form of useful analytics, value is created for the organization. Data in the Value Pipeline is updated on a continuous basis, but code is kept constant.
A scenario to be avoided is for poor quality data to enter the Value Pipeline, as this has a detrimental effect on the output usefulness. DataOps prevents this by implementing data tests. Inspired by the SPC, data tests ensure that data values follow expected statical distributions and/or lay within acceptable ranges. Data tests validate data values at the inputs and outputs of each processing stage in the pipeline. Once data tests are in place, they work to guarantee the integrity of the Value Pipeline. If anomalous data flows through the pipeline, the data tests catch it and take action – in most cases this means sending an automated alert to the data team responsible who can investigate. SPC encodes this process into the software, ultimately minimizing manual work and allowing the team members to focus on their other major responsibility – the Innovation Pipeline.
The Innovation Pipeline
The Innovation Pipeline seeks to improve analytics by implementing new ideas that yield analytic insights. As per software practices, a new feature undergoes development before it can be deployed to production systems. The Innovation Pipeline creates a feedback loop. Innovation spurs new questions and ideas for enhanced analytics. This requires more development leading to additional insight and innovation. During the development of new features, code changes, but data is kept constant. Keeping data static prevents changes in data from being falsely attributed to the impact of the new algorithm. A fixed data set can be setup when creating a development environment.
DataOps implements continuous deployment of new ideas by automating the workflow for building and deploying new analytics. It reduces the overall cycle time of turning ideas into innovation. While doing this, the development team must avoid introducing new analytics that break production. The DataOps enterprise uses logic tests to validate new code before it is deployed. Logic tests ensure that data matches business assumptions.
With logic tests in place, the development pipeline can be automated for continuous deployment, simplifying the release of new enhancements and enabling the data analytics team to focus on the next valuable feature. With DataOps the dev team can deploy without worrying about breaking the production systems. This is a key characteristic of a fulfilled, productive team.
The Value-Innovation Pipeline
The two workflows are combined into the Value-Innovation Pipeline in the figure below. The Value-Innovation Pipeline captures the interplay between development and production, and between data and code. DataOps breaks down this barrier so that cycle time and quality can be improved. The practices it employs help orchestrate data to production and the deployment of new features, while maintaining quality. DataOps speeds the extraction of value from data and improves the velocity of new development while ensuring the quality of data and code in production systems.
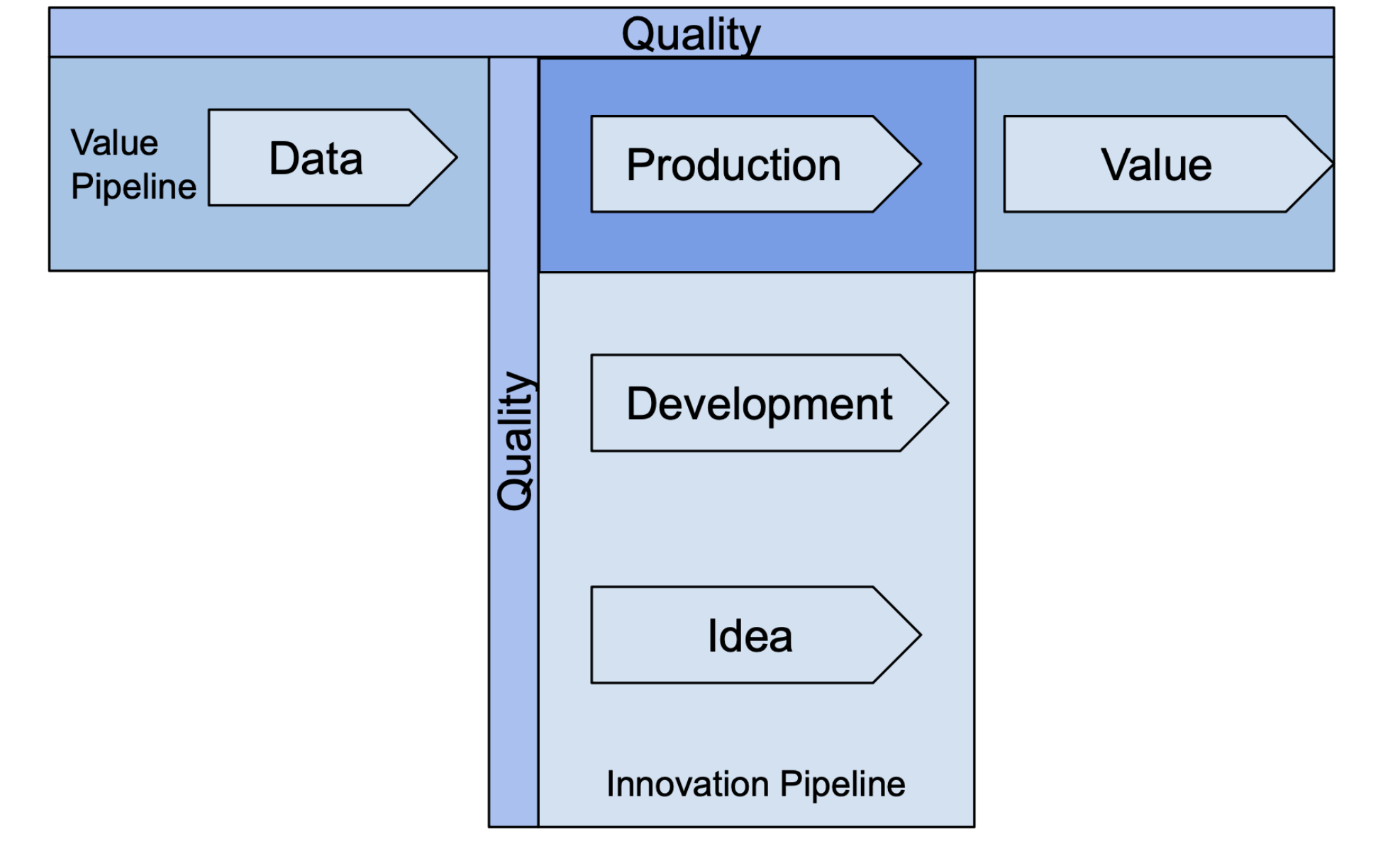
Process
Development and Deployment
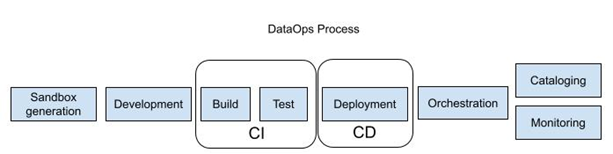
DataOps builds upon the DevOps development model. The DevOps process flow includes a series of steps that are common to software development projects:
- Develop – create/modify an application
- Build – assemble application components
- Test – verify the application in a test environment
- Deploy – transition code into production
- Run – execute the application
DevOps introduces three foundational concepts: Continuous Integration (CI), Continuous Delivery (CD) and Continuous Deployment. The goal of Continuous Integration is to enable an automated way to build, package, and test applications. Continuous Delivery is tasked with automating the delivery of applications to a given environment via manual release process. Finally, Continuous Deployment is the process of automatically releasing source code to a production environment.
Once an application passes all qualification tests, it is deployed to production. Together CI and CD resolve the main constraint hampering Agile development. Before DevOps, Agile created a rapid succession of updates and innovations that would stall in a manual integration and deployment process. With automated CI and CD, DevOps has enabled companies to update their software many times per day.
Testing
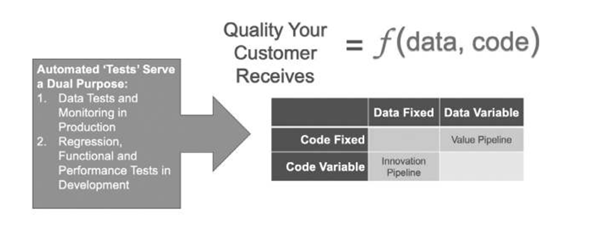
Tests in DataOps have a role in both the Value and Innovation Pipelines. In the Value Pipeline, tests monitor the data values flowing through, to catch anomalies or flag data values outside statistical norms. In the Innovation Pipeline, tests validate new analytics before deploying them.
In DataOps, tests target either data or code. The Figure below illustrates this concept. Data that flows through the Value Pipeline is variable and subject to SPC and monitoring. Tests target the data which is continuously changing. Analytics in the Value Pipeline, on the other hand, are fixed and change only using a formal release process. In the Value Pipeline, analytics are revision controlled to minimize any disruptions in service that could affect the data pipeline.
In the Innovation Pipeline code is variable and data is fixed. The analytics are revised and updated until complete. Once the sandbox (analytics development environment) is set up, the data usually doesn’t change. In the Innovation Pipeline, tests target the code (analytics), not the data. All tests must pass before promoting (merging) new code into production. A good test suite serves as an automated form of impact analysis that runs on any and every code change before deployment.
Some tests are aimed at both data and code. For example, a test that makes sure that a database has the right number of rows helps your data and code work together. Ultimately both data tests and code tests work together to ensure output quality.
Sandbox and test data management
When an engineer joins a software development team, one of their first steps is to create a "sandbox." A sandbox is an isolated development environment where the engineer can write and test new application features, without impacting teammates who are developing other features in parallel.
In order to create a dev environment for analytics, you have to create a copy of the Value Pipeline. This requires the data professional to replicate data which may have security, governance or licensing restrictions. It may be impractical or expensive to copy the entire data set, so some thought and care is required to construct a representative data set. Once a data set is sampled or filtered, it may have to be cleaned or redacted (have sensitive information removed). The data also requires infrastructure which may not be easy to replicate due to technical obstacles or license restrictions.
The concept of test data management is a first order problem in DataOps whereas in most DevOps environments, it is an afterthought. To accelerate analytics development, DataOps has to automate the creation of development environments with the needed data, software, hardware and libraries so innovation keeps pace with Agile iterations.
Data Lineage and Cataloging
Generating high quality data assets happens with a particular business need in mind. Dashboards, reports and bespoke applications are example beneficiaries of a piece of data. However, as time passes by, it becomes difficult to understand the interdependencies of systems partaking in producing and consuming data assets inside an organization. Being able to understand the importance of a data asset and its impact on other systems, allows for data teams to design and implement adequate software and processes correspondingly. Hence, data lineage is an important part of the DataOps process.
Yet, it is orthogonal to the Value-Innovation pipeline, in that it delivers business value indirectly. Another such activity stems from the nature of data. Besides their intended purpose, the high quality data assets that are generated can be used for unexpected and initially unintended goals. By making discoverable curated labels and metadata about data assets a data catalog helps foster collaboration and work reuse.
Lastly, this catalog needs to treat data assets as items in an online shop. Each item should have a dedicated section where LoB representatives can give feedback about it to the corresponding data stewards. This will effectively close the feedback loop and bring business value as LoB collaborates to uncover the inherent complexity of their domain of work by continuously refining the available data assets.
Organizational effect
DevOps strives to help data and operations teams work together in an integrated fashion. The data team typically consists of data analysts, data scientists and data engineers who are responsible for creating data analytics products and quality data assets.
The operations team supports and monitors the data pipeline. These are cloud engineers, but also customers – the users who create and consume analytics. DataOps enables them to work closer together.
Freedom vs. Centralization
DataOps also brings the organization together across another dimension - data analytics. As data is becoming increasingly used throughout the business, it is natural to expect that data analytics development occurs increasingly throughout enterprise, in the business units and close to domain expertise. These analytics will naturally be developed using self-service tools such as Power BI, Alteryx, Excel or KNIME. These local teams, engaged in decentralized, distributed analytics creation play an essential role in delivering data-driven innovation to the business. Empowering these pockets of creativity maintains the enterprise's competitiveness, but a lack of governance and guidelines can increase the risk of work duplication and collaboration opportunity loss.
Centralizing analytics development under the control of one group, such as IT, enables the organization to standardize metrics, control data quality, enforce security and governance, and eliminate islands of data. The issue is that too much centralization risks of inhibiting creativity.
One important benefit of DataOps is its ability to harmonize the back-and-forth between the decentralized and centralized development of data analytics — the tension between centralization and freedom. In a DataOps enterprise, new analytics originate and undergo refinement in the local pockets of innovation. When an idea proves useful or is worthy of wider distribution, it is promoted to a centralized development group who can more efficiently and robustly implement it at scale.
DataOps brings localized and centralized development together enabling organizations to reap the efficiencies of centralization while preserving localized development — the tip of the innovation spear.
Competences and Roles
Looking closer into the data and operations teams, we find a set of competences necessary for extracting business value out of data. These are as follows:
- Business knowledge – understanding the domain the company operates in
- Data knowledge - understanding the data landscape with the organization that represents the domain in question
- Data management skills - ability to perform operations ETL on data
- Analytics skills - ability to explore the data
- Software engineering skills - ability to develop, maintain and operate
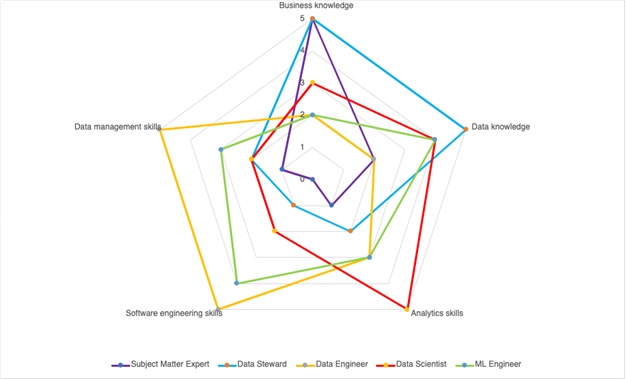
The above diagram shows the distribution and overlap of these competences among the key roles that partake in the generation of a data asset. Those roles and their intersection are described below.
Subject-Matter Expert (SME)
The SME is a representative of the business. It is a role that represents a substantial amount of domain knowledge on a given subject. These professionals have an interest in extracting business insight from data as seen from their respective business context.
They interface with:
- Data Stewards - in the process of data-refinement - where they provide feedback for the generated data assets
- Data Scientists/Data Analysts – by giving context on the problems that are solved and the acceptance criteria for a given data analytics solution
Data Steward
Typically, they are tech-savvy SMEs, the Data Steward is the primary point of contact regarding data assets.
They interact with:
- Data Engineers – with whom they establish Service Level Indicators (SLI) that drive Service Level Objectives (SLO)
- SMEs - with whom they engage in data asset refinement
- All data roles – to whom they communicate Service Level Agreements (SLA) regarding the data asset(s) they own
Data Engineer
A technical role that has the ability to manipulate data at scale. Those could be people with traditional software engineering background or tech-savvy representatives of LoB. The primary output of a Data Engineer is a data pipeline that leverages a toolbox spanning from code-centric solutions to visual "drag-and-drop" tools.
They engage with:
- Data Scientists – by providing data in the right location, shape and amount
- Data Stewards – who give necessary domain context when defining SLIs towards SLOs
- ML Engineers – by collaborating integrate a machine learning model as part of an end-to-end data pipeline
Data Scientist
A technical role with the capability to extract insights out of data. The primary output of a Data Scientist is the desired business insight. That is achieved via the application of statistical methods which are applied to data and ultimately yield a machine learning model. The model represents a snapshot of time with respect to the data and techniques used to generate it.
They conjoin their work with:
- Data Engineers – by providing requirements necessary for analysis of data
- SMEs – when learning the key features of the domain and the acceptance criteria for the insights that they should extract
- ML Engineers – when transferring ownership of machine learning models
ML Engineer
A technical role with the capability of putting machine learning models in operation at scale. It sits at the intersection between data, data science and cloud infrastructure.
They intersect with:
- Data Engineers – by collaborating to provide a scalable machine learning step to a data pipeline
- Data Scientists – when transitioning machine learning models in and out of use and scaling them to many users
Cloud Engineer
Albeit orthogonal to the data plane, the Cloud Engineer role is integral to every cloud solution. It provides the ability for all technical roles to utilize their capabilities in an environment that is secure, scalable and cost-effective. Keeping software up-to date, making sure that data products have high uptime and automating all procedures are the main tasks that a Cloud Engineer executes on a regular basis.
References
- DataOps Right - https://get.oreilly.com/ind_getting-dataops-right.html
- DataOps Cookbook - https://datakitchen.io/the-dataops-cookbook
N.B. For a narrated version of this document with examples on how DataOps can materialize from a technical and organization point of view, please refer to this video.
I would like to thank my colleagues from the Data & Analytics department in R&D at Leo Pharma for their time and feedback. I would very much like to thank my colleague Radu for the contributions, sparring, feedback and excellent research on inspirational resources.